文生産メカニズムの単位について
寺尾 康
本稿では日常生活で観察された,特に語の言い誤りを資料として文生産処理のレベルと単位についての考察を試みる。
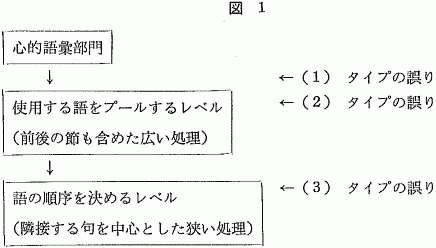
語のレベルでの誤りは次の2つの観点から計3つに分類することができる。即ち,語の代用[(1) と (2)]か語の交換[(3)]か,誤りの源となった語が前後の発話中に見出せる[(2) と (3)]か見出せない[(1)]か,である。
(1) ネズミがのたくったような字(←ミミズ)
(2) センターによじのぼったセンターの弘田(←フェンスによじのぼった)
(3) 町は学校にあった(←学校は町に)
ここで,意図した語と誤った語の意味論的語用論的,および音声的(アクセント型,モーラ数,語頭音)特徴を調べてみると (1) タイプだけに著しい一致がみられた。また,誤りが起きた環境を調べてみると,(2) タイプでは60%の実例が節境界を越えてかなり遠く(平均距離6.2モーラ)から語が侵入してきているのに対し,(3) タイプの誤りでは隣接する句にある2語が交換されている実例が70%を超えるという点て相遠がみられた。以上の事実から,文生産の過程には,合理的に語を選択するレベル,使用する語をプールしておくレベル,隣接する語を中心に語の順序を決めていくレベルの3つのレベルが存在すると仮定され,本務であげた実例 (1),(2),(3) はそれぞれのレベルで起こると考えられる。(図1参照)また,(4) に示す音位転倒の誤りでは,隣接するモーラが交換されることが多いという事実を考え合わせると,
(4) つとぎ先(←とつぎ先)
言語学的レベルが異なるだけで,隣接する要素を中心に順序を決めてゆくという処理の単位は文生産過程で重要な役割を演じているように思われる。